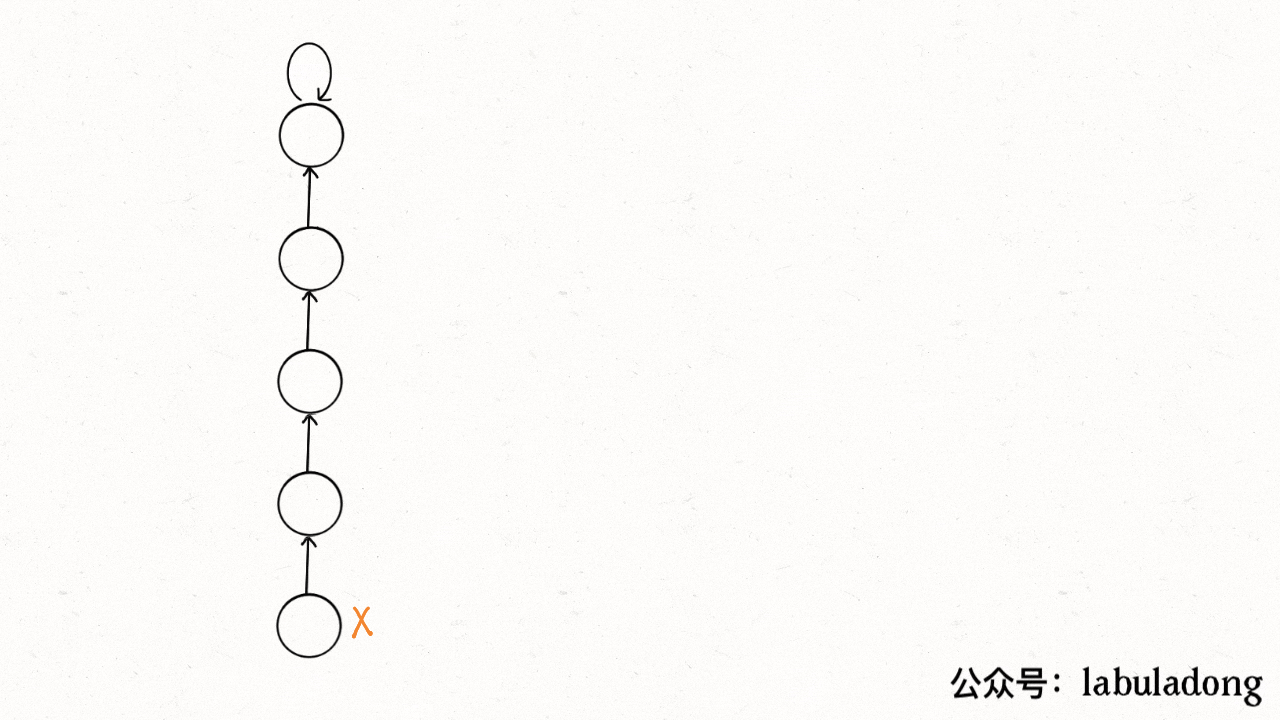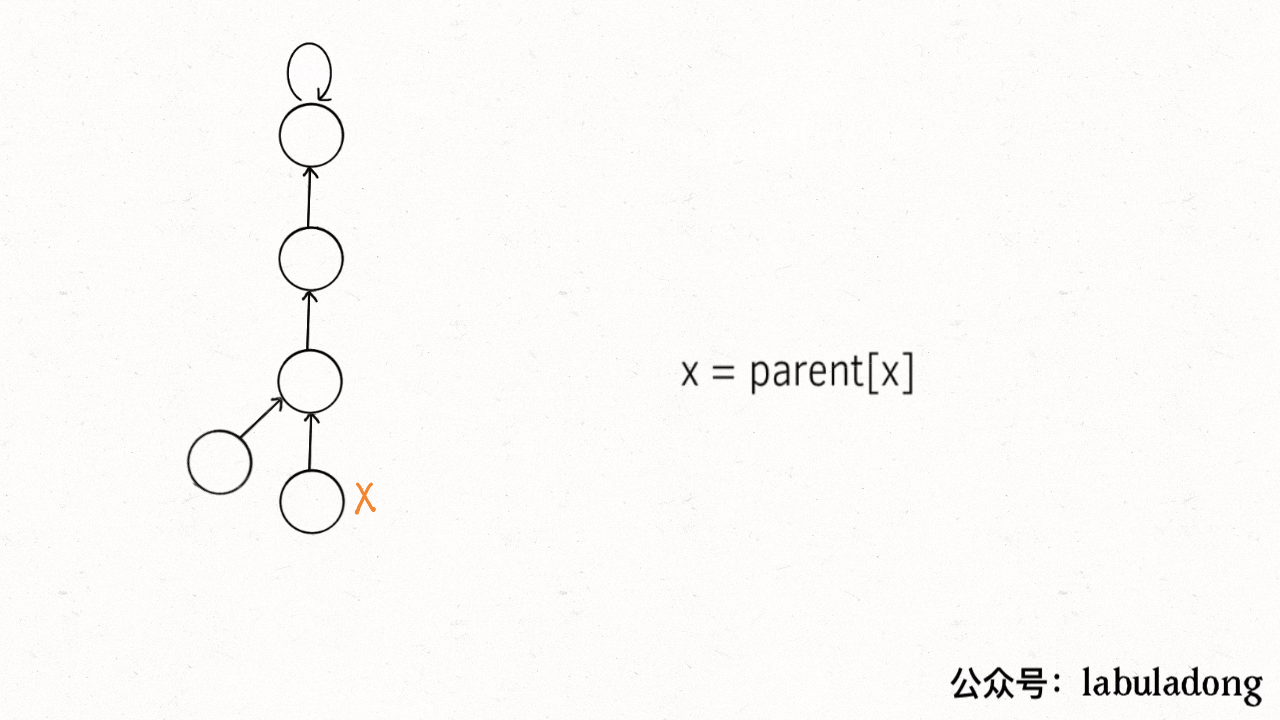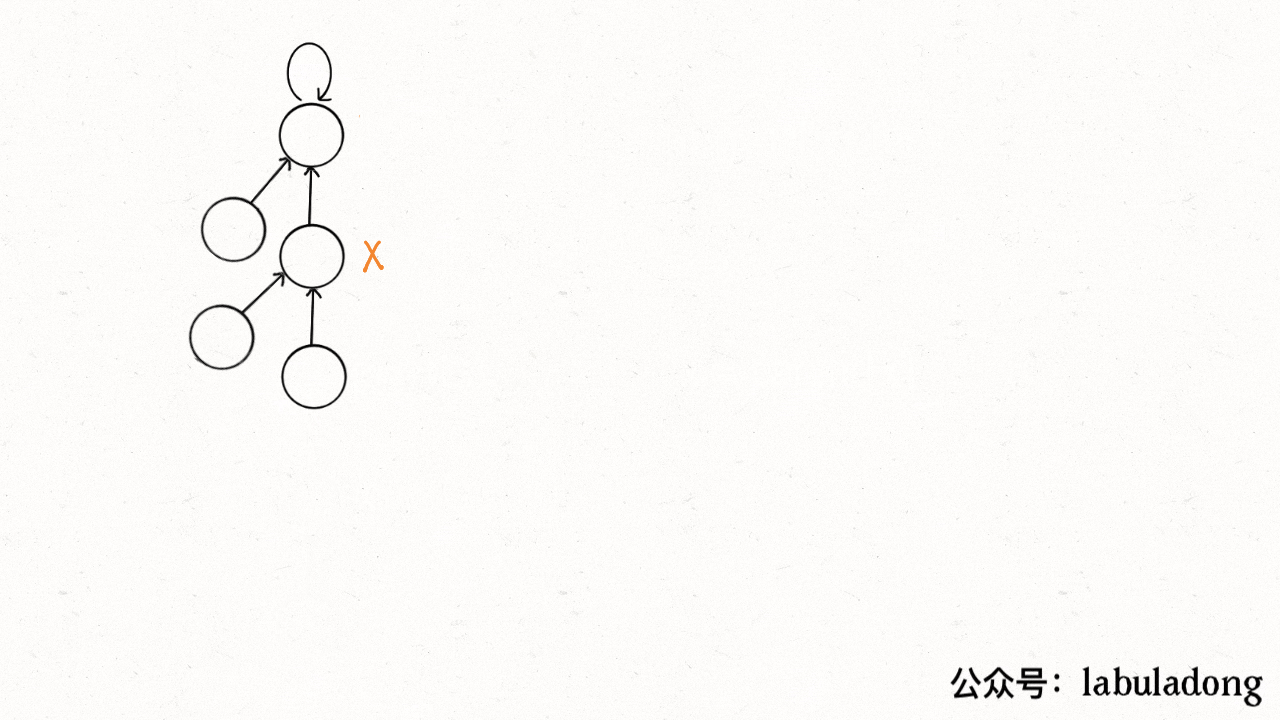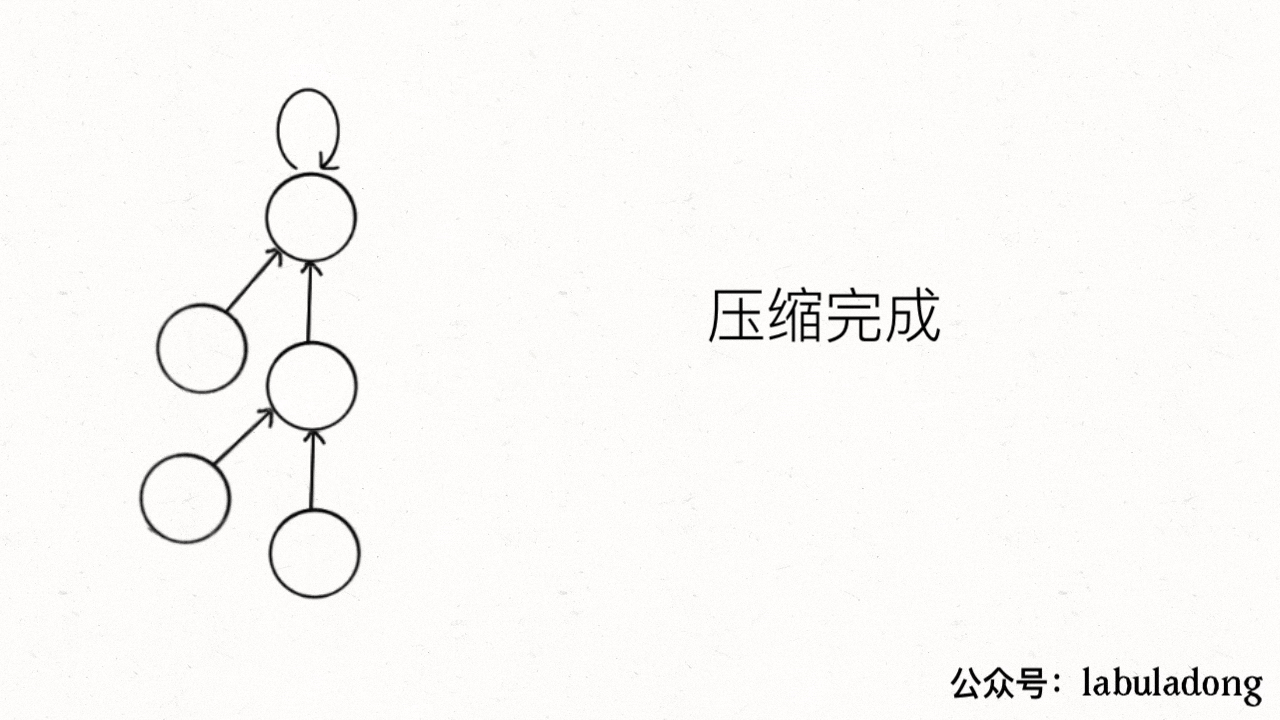本文最后更新于:August 26, 2022 pm
算法简介 并查集算法也就是常说的并查集结构,主要是解决图论中的「动态连通性」问题的。
class UF public void union (int p, int q) public boolean connected (int p, int q) public int count ()
这里说的「连通」是一种等价关系,也就是说具有如下三个性质:
自反性:节点 p 和 q 是连通的。
对称性:如果节点 p 和 q 连通,那么 q 和 p 也连通。
传递性:如果节点 p 和 q 连通,q 和 r 连通,那么 p 和 r 也连通。
基本思路 假设树的每个节点有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class UF private int count;private int [] parent;public UF (int n) this .count = n;new int [n];for (int i = 0 ; i < n; i++) {
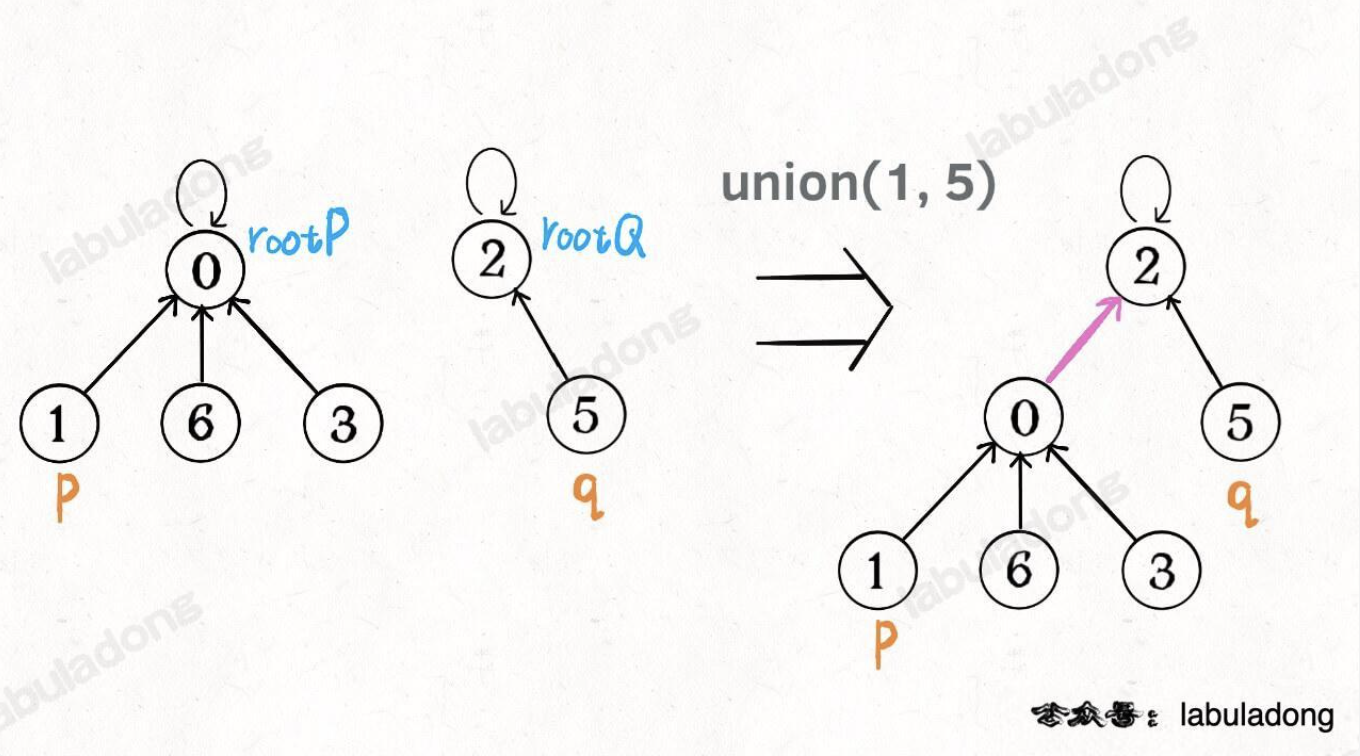
如果两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上;也就是说如果节点 p 和 q 连通的话,它们一定拥有相同的根节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public void union (int p, int q) int rootP = find(p);int rootQ = find(q);if (rootP == rootQ) {return ;private int find (int x) while (parent[x] != x) {return x;public int count () return count;public boolean connected (int p, int q) int rootP = find(p);int rootQ = find(q);return rootP == rootQ;
算法复杂度
connected和union中的复杂度都是find函数造成的,它们的复杂度和find一样。find主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。树的高度不一定就是 logN,logN 的高度只存在于平衡二叉树,对于一般的树可能会出现极端不平衡的情况,使得「树」几乎退化成「链表」,最坏情况下可能变成 N。
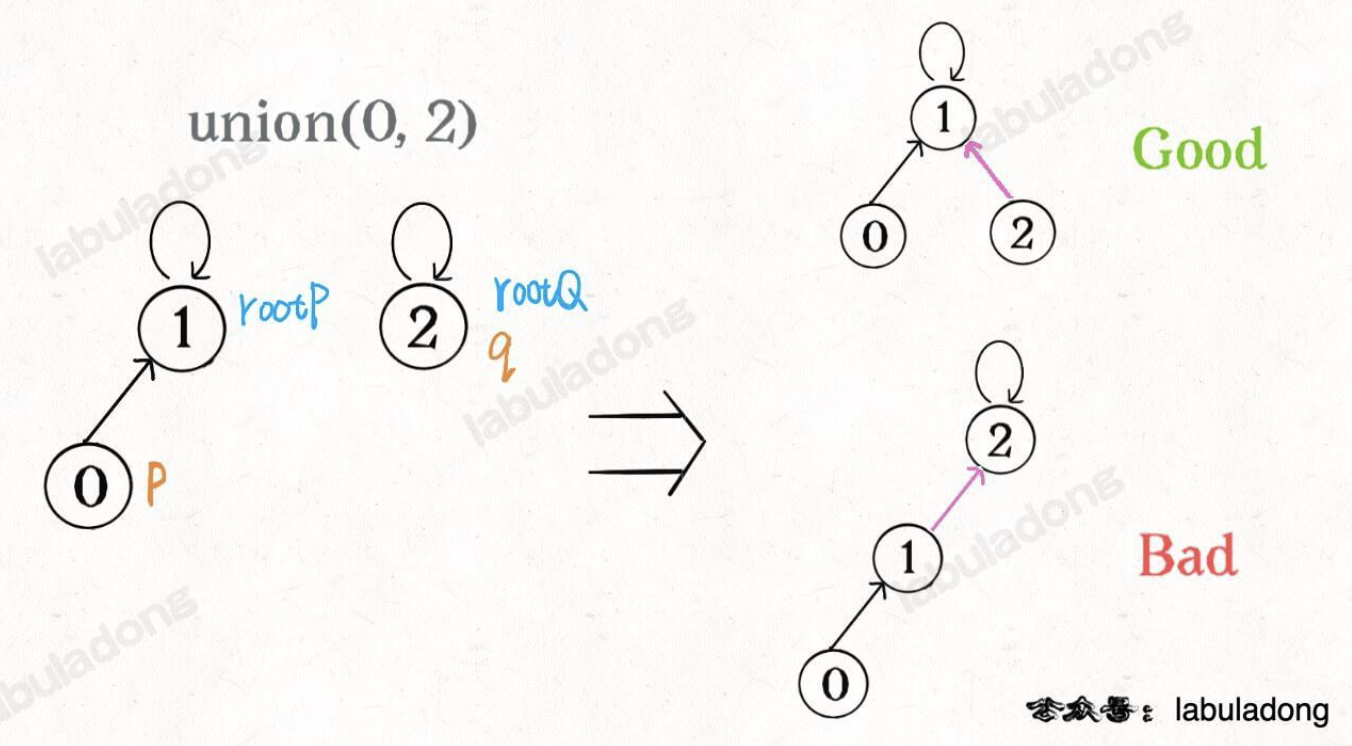
平衡性优化 由上面的代码可以知道,union过程是直接把p所在的树接到q所在的树的根节点下面,那么就很有可能会出现不平衡的现象。比如下图所示:
为了解决这个问题,提出了「重量」的概念,额外使用一个size数组,记录每棵树包含的节点数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class UF private int count;private int [] parent;private int [] size;public UF (int n) this .count = n;new int [n];new int [n];for (int i = 0 ; i < n; i++) {1 ;public void union (int p, int q) int rootP = find(p);int rootQ = find(q);if (rootP == rootQ)return ;if (size[rootP] > size[rootQ]) {else {
此时,find,union,connnected的时间复杂度都下降为O(logN),因为可以保证树的生长相对平衡,树的高度大致在logN的数量级。
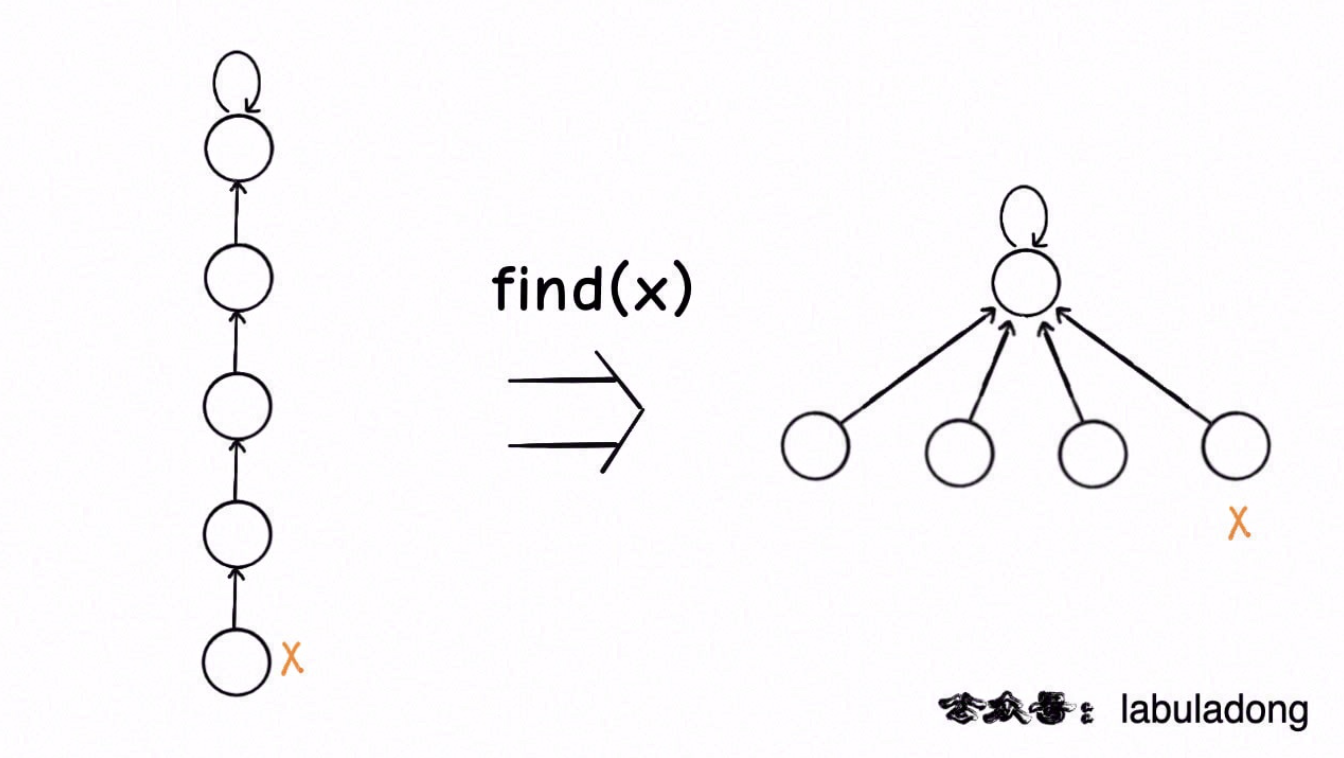
路径压缩 由于并查集算法实际上关注的是根节点,并不在乎树是怎么样的,所以可以考虑进一步来压缩树的高度,让树高保持为常数。
下面是修改find函数的两种方法。
private int find (int x) while (parent[x] != x) {return x;
第二种写法:
public int find (int x) if (parent[x] != x) {return parent[x];
第二种递归写法的压缩效率是比第一种迭代写法高的,但较难理解。压缩效果如下:
可以看出第二种方法能够直接把树降低到最小高度,因此推荐使用这种路径压缩算法。而且使用路径压缩算法以后,size数组的平衡优化就基本不需要了。
下面就是Union Find算法实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class UF private int count;private int [] parent;public UF (int n) this .count = n;new int [n];for (int i = 0 ; i < n; i++) {public void union (int p, int q) int rootP = find(p);int rootQ = find(q);if (rootP == rootQ)return ;public boolean connected (int p, int q) int rootP = find(p);int rootQ = find(q);return rootP == rootQ;public int find (int x) if (parent[x] != x) {return parent[x];public int count () return count;
总结 对于Union Find复杂度,构造初始化数据结构需要 O(N) 的时间和空间复杂度,union,connected和count方法所需时间复杂度为O(1)。
主要应用:解决动态连通性问题。
算法题 无向图中连通分量的数目 leetcode-323. 无向图中连通分量的数目
给你输入一个包含 n 个节点的图,用一个整数 n 和一个数组 edges 表示,其中 edges[i] = [ai, bi] 表示图中节点 ai 和 bi 之间有一条边。请你计算这幅图的连通分量个数。
这道题可以直接套用并查集算法解决,代码如下:
public int countComponents (int n, int [][] edges) new UF(n);for (int [] e: edges) {0 ], e[1 ])return uf.count();class UF
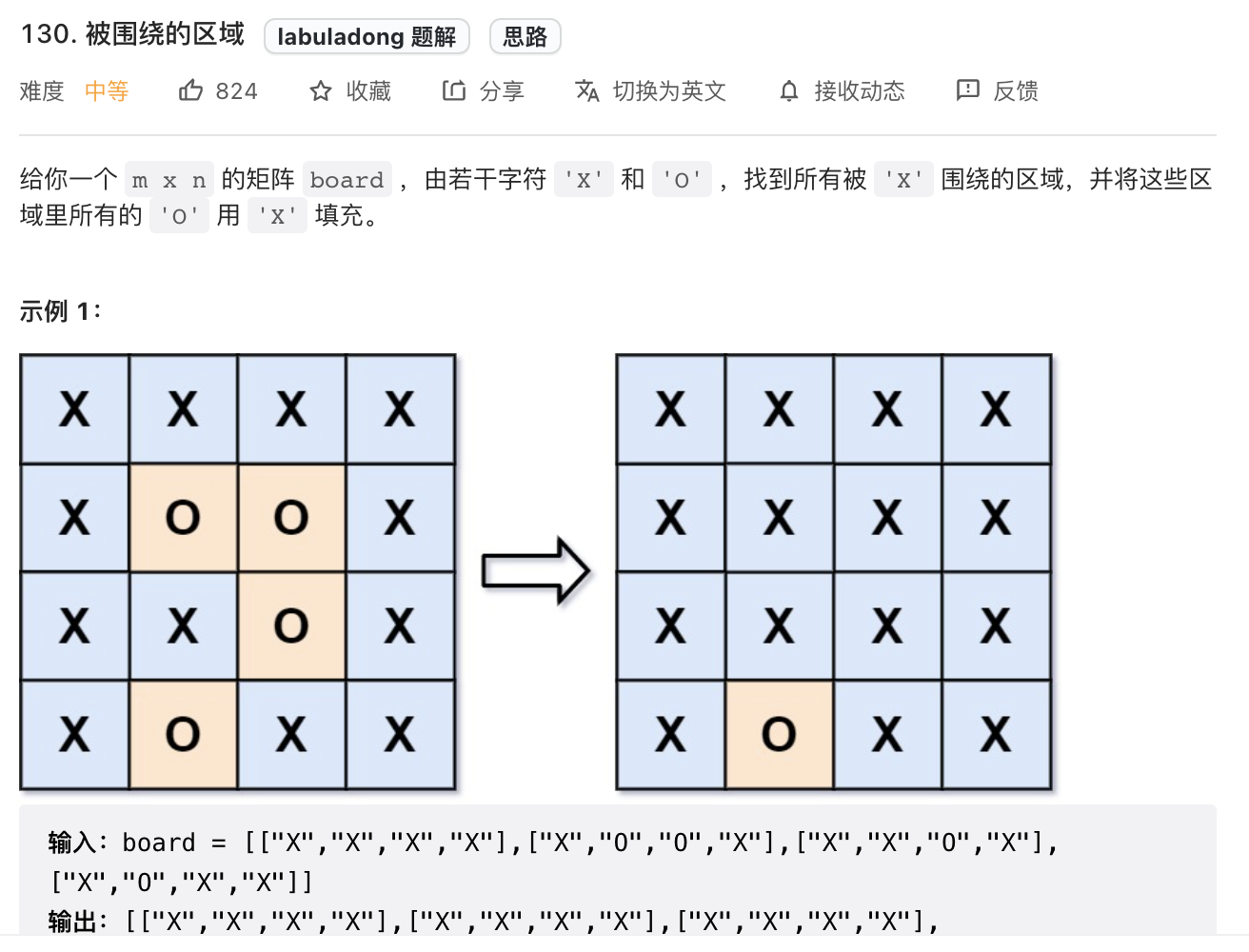
被围绕的区域 leetcode-130. 被围绕的区域
其实这一题应该归于dfs问题,由题意可知边界上的O是不会被填充的,遍历棋盘的四边,用dfs算法找到与边界相连的O,并换成一个特殊字符;然后便遍历整个棋盘,把剩下的O换成X,再把特殊符号还原为0。
当然也可以使用并查集算法来解决,虽然效率更低。
思想:把不需要替换的 O看成是特殊的一类,他们有一个共同的祖先 dummy,这些O与dummy互通,那些需要被替换的O与dummy不互通。
并查集算法底层使用的是一维数组,而题目给出的是二维数组,因此这里需要有一个降维的过程,将二维坐标(x, y)转换成x * n + y。注意还需要给dummy留一个位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 void solve (char [][] board) if (board.length == 0 ) {return ;int m = board.length;int n = board[0 ].length;new UF(m * n + 1 );int dummy = m * n;for (int i = 0 ; i < m; i++) {if (board[i][0 ] == 'O' )if (board[i][n - 1 ] == 'O' )1 , dummy);for (int j = 0 ; j < n; j++) {if (board[0 ][j] == 'O' )if (board[m - 1 ][j] == 'O' )1 ) + j, dummy);int [][] d = new int [][]{{1 , 0 }, {0 , 1 }, {0 , -1 }, {-1 , 0 }};for (int i = 1 ; i < m - 1 ; i++) for (int j = 1 ; j < n - 1 ; j++) if (board[i][j] == 'O' )for (int k = 0 ; k < 4 ; k++) {int x = i + d[k][0 ];int y = j + d[k][1 ];if (board[x][y] == 'O' )for (int i = 1 ; i < m - 1 ; i++) for (int j = 1 ; j < n - 1 ; j++) if (!uf.connected(dummy, i * n + j))'X' ;class UF
等式方程的可满足性 leetcode-990. 等式方程的可满足性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 boolean equationsPossible (String[] equations) new UF(26 );for (String eq : equations) {if (eq.charAt(1 ) == '=' ) {char x = eq.charAt(0 );char y = eq.charAt(3 );'a' , y - 'a' );for (String eq : equations) {if (eq.charAt(1 ) == '!' ) {char x = eq.charAt(0 );char y = eq.charAt(3 );if (uf.connected(x - 'a' , y - 'a' ))return false ;return true ;class UF
参考
并查集(Union-Find)算法详解 :: labuladong的算法小抄